1 min to read
我的2018

生物实验
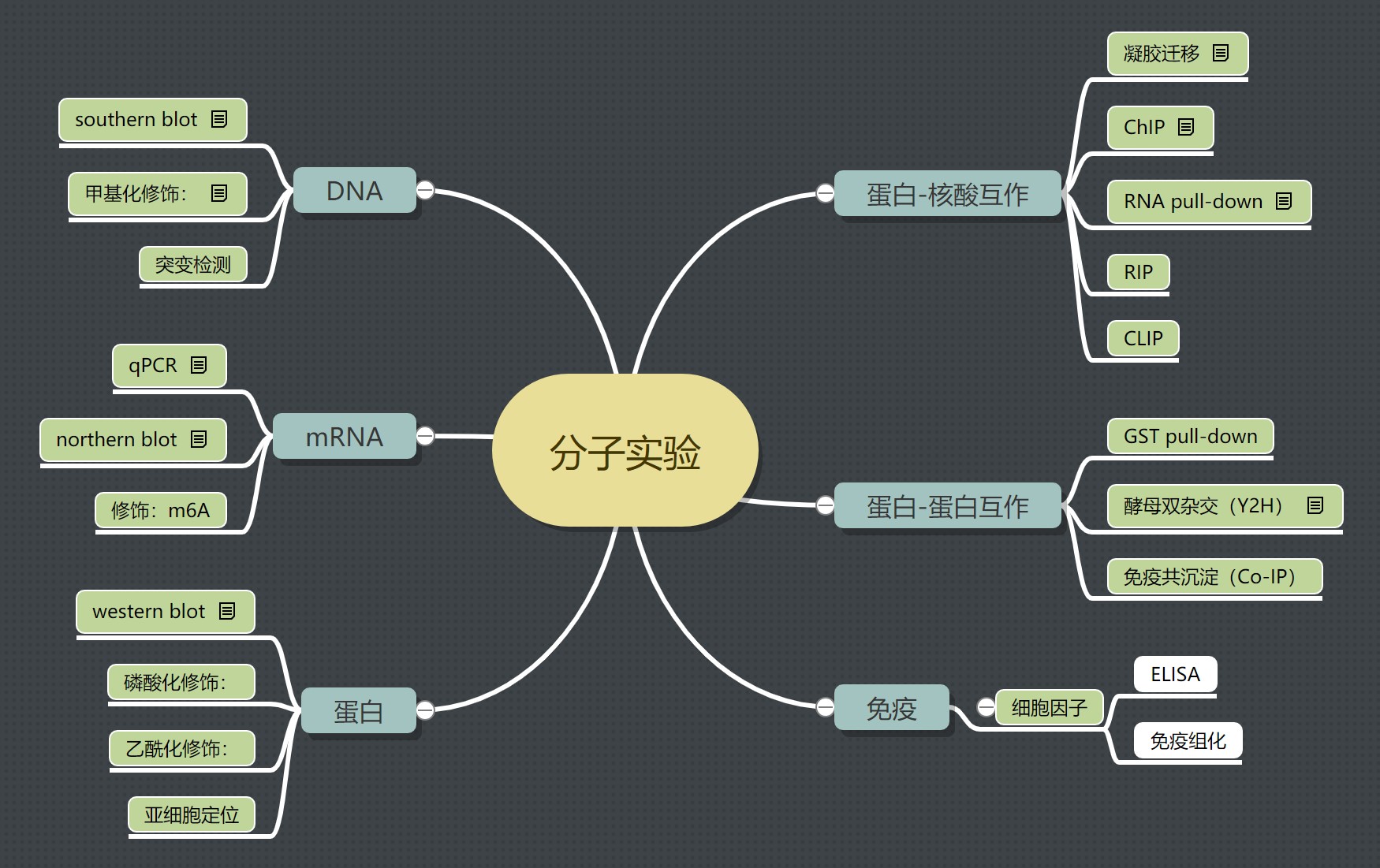
分子生物学实验
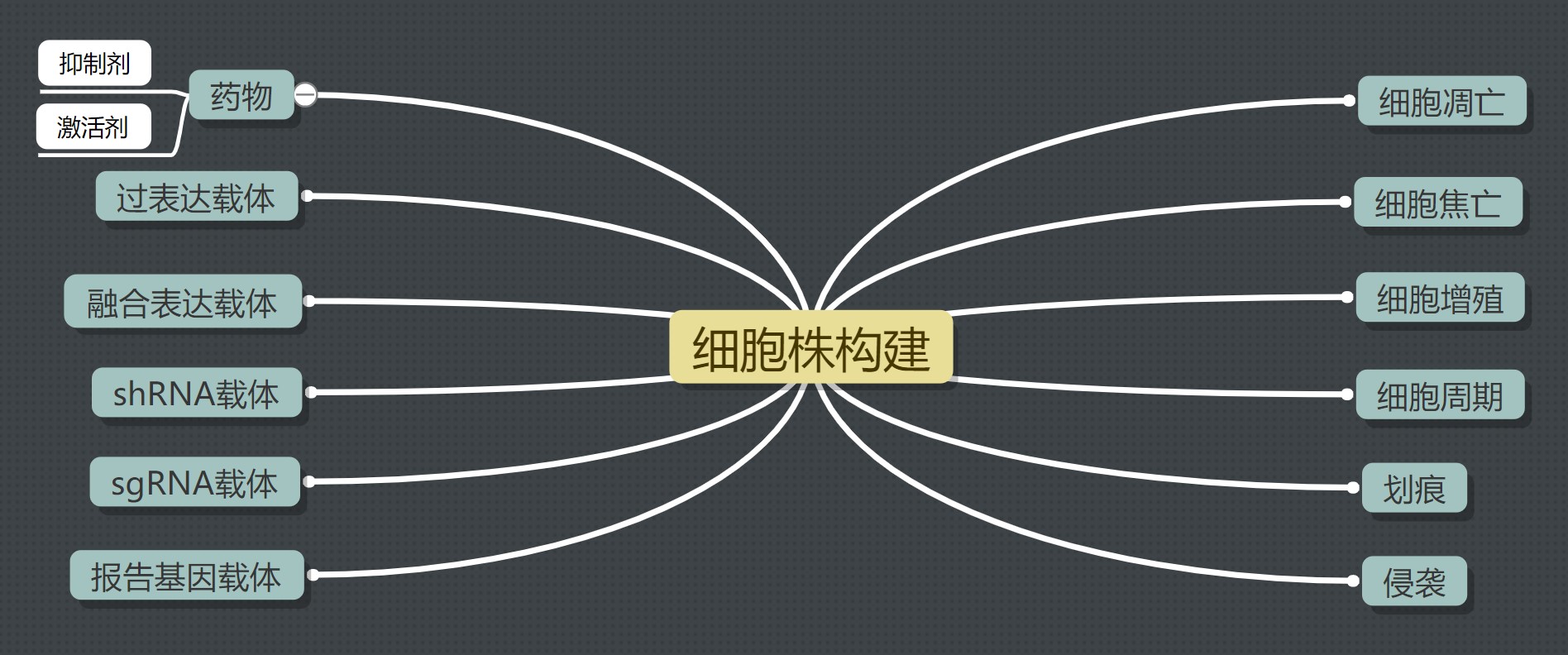
细胞生物学实验
生物信息
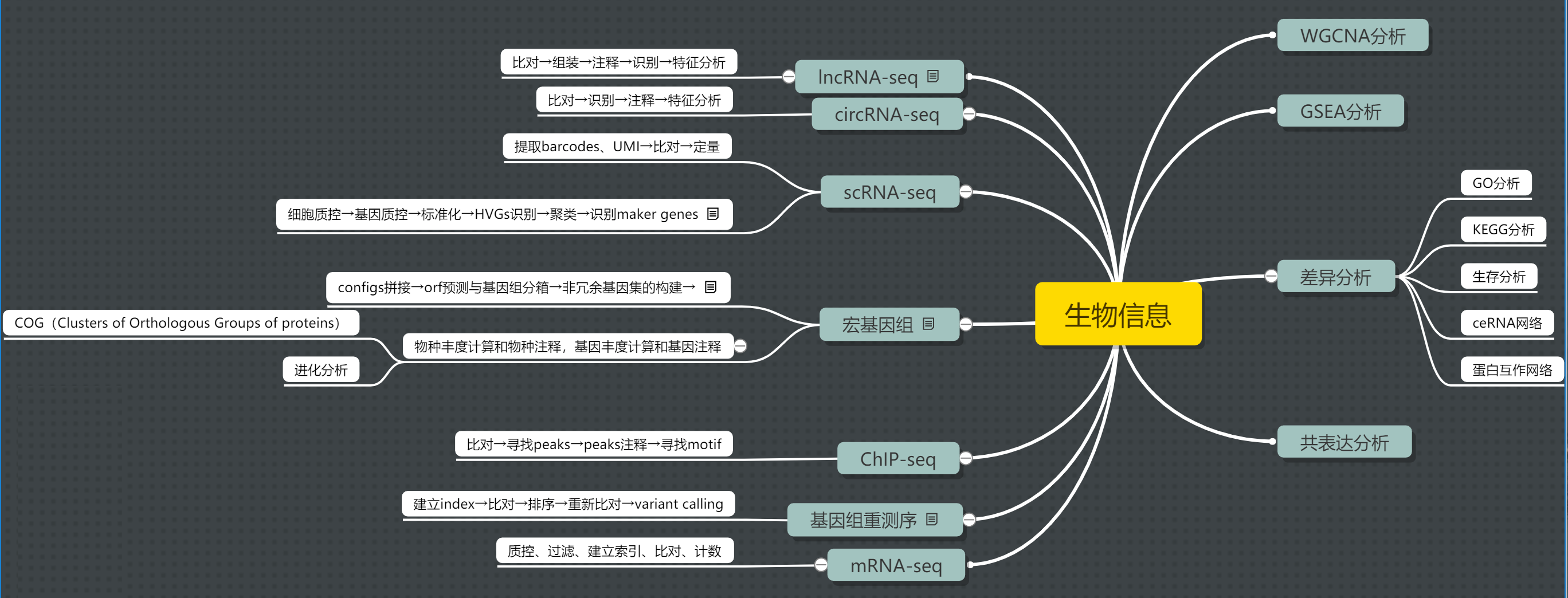
后续若工作有需要将继续学习代谢组分析、蛋白组分析、蛋白质三维结构预测、药物模拟筛选。
Python
爬虫
框架相关包scrapy、PySpider。PySpider支持分布式架构、强大的webUI、消息队列。
网络请求相关包urllib、Requests 。get请求和post请求,如果请求的页面每次需要身份验证,我们可以使用 Cookies来自动登录。Selenium、splinter(基于浏览器的开源自动化测试工具)可以模拟用户操作浏览器,可以驱动真实浏览器和无头浏览器(PHantomJs)。对于反扒的网站可以采用代理IP来做。对于APP,可以使用抓包工具Fiddler、Wireshark实现。
网页解析相关包beautifulsoap、lxml、html.parser、PyQuery。结构化解析网页,以DOM树结构为标准,进行标签结构信息的提取。按名称、属性和文本搜索节点(xpath和CSS选择器 )和访问节点。正则表达式用于提取非结构化的数据。
数据存储于MySQL(pymysql)、MongoDB、redis、SQLite(sqlite3)。
机器学习
常用的数据处理相关的包有NumPy、SciPy、Pandas、Statsmodels、SciKit-Learn,可视化相关的包Matplotlib、Seaborn、Bokeh、Plotly、pyecharts。
贝叶斯:朴素贝叶斯算法,平均单依赖估计(Averaged One-Dependence Estimators, AODE),以及Bayesian Belief Network(BBN)。
回归:最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regression),逐步式回归(Stepwise Regression),多元自适应回归样条(Multivariate Adaptive Regression Splines)以及本地散点平滑估计(Locally Estimated Scatterplot Smoothing)。
正则化:Ridge Regression, Least Absolute Shrinkage and Selection Operator(LASSO),以及弹性网络(Elastic Net)。
聚类: k-Means算法以及期望最大化算法(Expectation Maximization, EM)。
关联规则:Apriori算法和Eclat算法。
降维:主成份分析(Principle Component Analysis, PCA),偏最小二乘回归(Partial Least Square Regression,PLS), Sammon映射,多维尺度(Multi-Dimensional Scaling, MDS), 投影追踪(Projection Pursuit)等。
决策树:分类及回归树(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 随机森林(Random Forest), 多元自适应回归样条(MARS)以及梯度推进机(Gradient Boosting Machine, GBM)。
基于核的算法:支持向量机(Support Vector Machine, SVM), 径向基函数(Radial Basis Function ,RBF), 以及线性判别分析(Linear Discriminate Analysis ,LDA)等。
集成算法:Boosting, Bootstrapped Aggregation(Bagging), AdaBoost,堆叠泛化(Stacked Generalization, Blending),梯度推进机(Gradient Boosting Machine, GBM),随机森林(Random Forest)。
深度学习
常用的包包括tensorflow、keras、Pytorch(利用 GPU 来加速训练)、Caffe。
相关概念:梯度下降、学习率、dropout、损失函数。
卷积神经网络(CNN),包括输入层、卷积层、池化层、全连接层、ReLU激励层。
循环神经网络(RNN),用来处理序列数据,存在梯度消失与梯度爆炸、无法解决长期依赖的的问题。LSTM为解决上述问题在cell中加入keep gate、input gate、output gate,GRU中有重置门(reset gate)和更新门(update gate)。
对抗神经网络(GAN),通过生成网络G(Generator)和判别网络D(Discriminator)不断博弈,进而使G学习到数据的分布。
自编码神经网络,是一种无监督学习算法,是一种数据的压缩算法。
强化学习算法之一DQN,使用卷积神经网络作为价值函数来拟合Q-learning中的动作价值,DQN则基于Q-Learning来确定Loss Function,我们想要使q-target值和q-eval值相差越小越好,训练目标是随着训练过程在变化。通过Q-Learning使用reward来构造标签,通过experience replay(经验池,可以使下一步的行为分布基于之前许许多多的状态而平均化,避免学习结果震荡或发散)的方法来解决相关性及非静态分布问题。Spark力图整合机器学习(MLib)、图算法(GraphX)、流式计算(Spark Streaming)和数据仓库(Spark SQL)等领域,通过计算引擎Spark,弹性分布式数据集(RDD),架构出一个新的大数据应用平台。
javascript
d3.js
它结合强大的可视化组件来驱动 DOM 操作,动态属性,数据绑定的时候可能出现DOM元素与数据元素个数不匹配的问题,那么 enter 和 exit 就是用来处理这个问题的。enter 操作用来添加新的 DOM 元素,exit 操作用来移除多余的 DOM 元素。
vue.js
它是一套构建用户界面的渐进式框架。它是以数据驱动和组件化的思想构建的,采用自底向上增量开发的设计。vue 的官方调试工具vue Devtools,Vuex采用集中式存储管理应用的所有组件的状态。Vue 要实现异步加载需要使用到axios库。使用vue-cli来搭建整个项目,vue-cli就是一个脚手架。ES6语法和webpack的配置。
node.js
大数据工具
hadoop
Hadoop是一个分布式系统基础架构。包含分布式文件系统(Hadoop Distributed File System),资源管理架构 YARN,分布式运算编程框架(MapRuduce)。生态系统包括:Hive(数据仓库工具)、Hbase(Nosql数据库,Key-Value存储),Flume(日志收集工具),kafka(消息队列),storm(实时计算框架)。
spark
Spark是一个用来实现快速而通用的集群计算的平台。Spark的一个重要特点就是能够在内存中计算。每个Spark应用都由一个驱动器程序(drive program)来发起集群上的各种并行操作。驱动器程序包含应用的main函数,驱动器负责创建SparkContext,SparkContext可以与不同种类的集群资源管理器(Cluster Manager),例如Hadoop YARN,Mesos进行通信,获取到集群进行所需的资源后,SparkContext将得到集群中工作节点(Worker Node)上对应的Executor,之后SparkContext将应用程序代码发送到各Executor,最后将任务(Task)分配给executors执行
其他
mysql
MySQL 为关系型数据库。MySQL 通过执行 SQL 脚本来完成对数据库的操作。在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。navicat是一套数据库管理工具。
php
PHP是一种创建动态交互性站点的强有力的服务器端脚本语言。phpStudy集成最新的Apache+Nginx+LightTPD+PHP+MySQL+phpMyAdmin+Zend Optimizer+Zend Loader,一次性安装,无须配置即可使用,是非常方便、好用的PHP调试环境。PHP提供了多种方式来访问和操作Mysql数据库记录。
markdown
Markdown是一种轻量级且易使用的标记语言,通过对标题、正文、加粗、链接等主要文本格式的预设编码,帮用户在写作中有效避免频繁的格式调整。
Latex
LaTeX, 是一种基于TEX的排版系统,对于生成复杂表格和数学公式,这一点表现得尤为突出。可以用于书籍、简历、cheat sheet排版。LaTeX 的工作方式类似 web page。
linux shell
文件和目录操作,管道、标准输入输出操作。软件安装两种方法:通过源码安装(执行“./configure”命令为编译做好准备【./configure --prefix=/usr/local/aaaa制定安装目录】,执行“make”命令进行软件编译,执行“make install”完成安装,执行“make clean”删除安装时产生的临时文件),通过 apt-get 在线安装。文本处理命令(grep、sed、awk),可用于基因组注释信息的提取。

参考资料
[01]. Python 爬虫基础Selenium库的使用(二十二01)
[02]. Python+Requests接口测试教程(1):Fiddler抓包工具
[03]. 非码农也能看懂的“机器学习”原理
[04]. d3.js code snippets
[05]. 我的LaTeX入门
[06]. Latex demo
[07]. Latex排版全解

Comments